Today our new model for better text analysis goes online and improves our service immensely! Check it out Hive Discover (https://beta.hive-discover.tech)!

The new model is based on a total of almost 500,000 English Hive posts from you. All of them were prepared first, i.e. foreign and unknown words were removed and generally converted from Markdown to plain text so that they can be processed in the next step. We found quite interesting articles in random samples, but some of them were written years ago and are no longer read. Therefore, we gave them a "last use": to train our model. Unfortunately, we cannot and are not allowed to show which articles we have actually used now, as this is prohibited by the European GDPR. It only gives us the right to use contributions anonymously for scientific purposes. Therefore, we also saved all training posts anonymously.
Example Results by our new AI
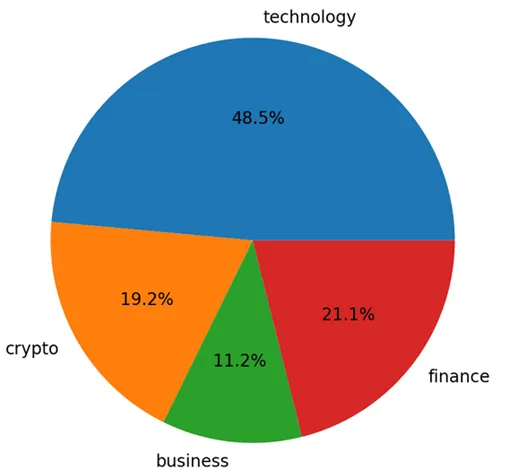
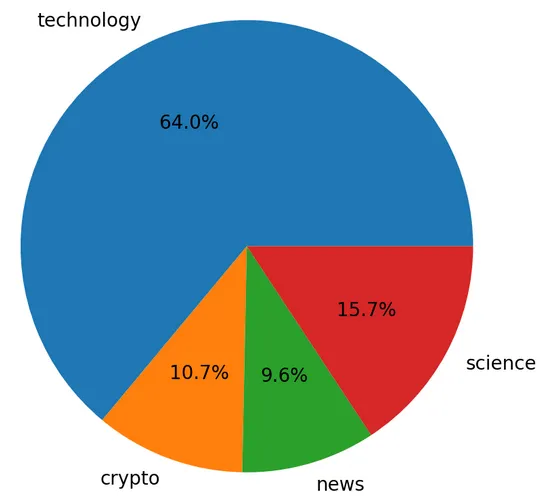
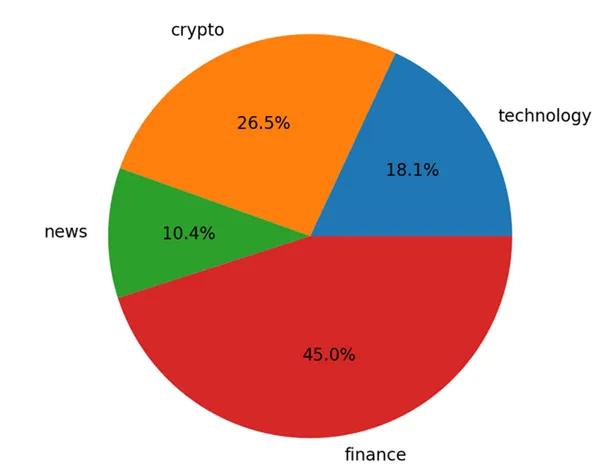
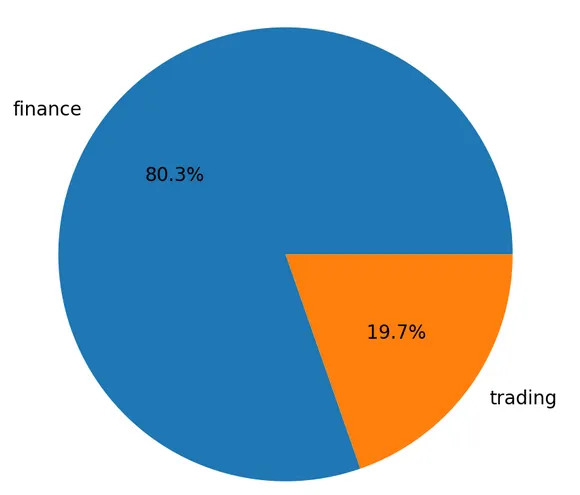
| An article from @rtonline dealing with Tim Cook (CEO of Apple) talking about Crypto (link) | A post from @aicoding talking about AI fighting against misinformation (link) | Content by @buff-news about states buying bitcoin (link) |
|---|---|---|
 |  |  |
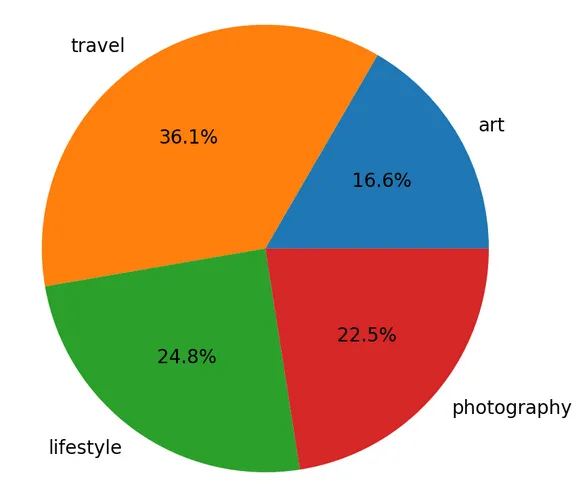
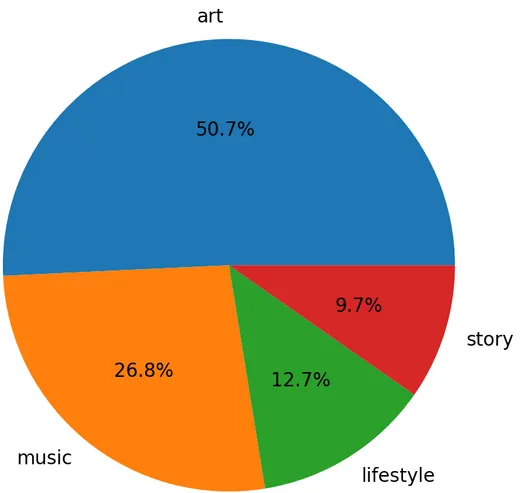
| A Travel report from Vietnam by @quyetien (link) | Another one from @buff-news about Warren Buffet (link) | A beautiful portrait with a music story by @inber (link) |
|---|---|---|
 |  |  |
How does text analysis actually work?
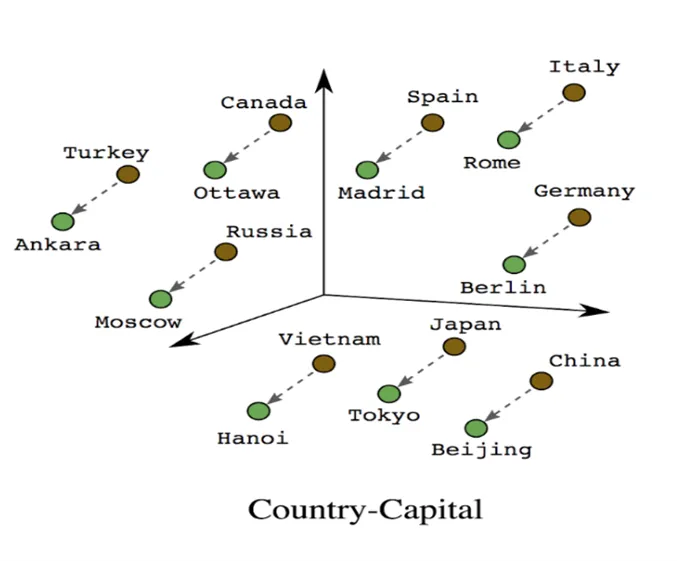
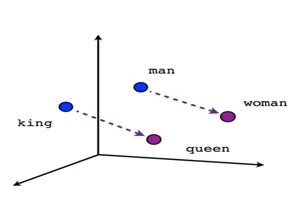
Every post that you write is analysed by our AI with regard to a total of 46 categories. For this purpose, the posts are first prepared as in training and foreign words, etc. are removed. Now we should have a list of words that our model knows from your post. But in order for a computer to be able to process texts at all, all words are converted into vectors. [ATTENTION MATH] These vectors then consist of 300 individual values (300 components) from 0 to 1 and present a word. What is special is that similar words also have similar vectors; for example, the vector of Madrid is closer to Spain than Berlin. You can also calculate with the vectors in the normal way. Thus, the vector to get a capital from a country is always the same in theory. Or you get the word "queen" by adding "king" and the difference between "man" and "woman"; thus:
 |  |
|---|
[END MATH] If you then have the post as a word-vector list, this represents a 2-dimensional table. One row per word with 300 columns for all components. Now, for efficiency reasons, we always pack several posts (with the same number of words) together so that we have a 3-dimensional object, which we then process in a neural network. First come a few convolutional layers, each involving a different number of words. These are the so-called filters, which then process the results via linear layers, so that at the end there are 46 individual values from 0 to 1. This graphic illustrates the whole thing again:
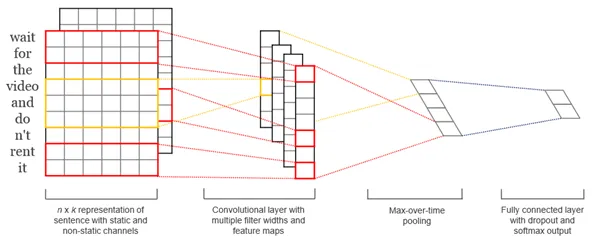
What happens next?
The first thing we plan to do after this is to finally open up our API. This goal, which we have been pursuing for a long time, is close to completion. The last documentation is being written. From then on, popular front-ends like @peakd, @ecency or @leofinance will be able to integrate our service and you won't even have to change pages to discover interesting content! The deadline is set for mid-December so far....
Any other questions left? - Just ask them in the comments
We would be very thankful for an upvote
Your action-chain