Firstly, I have to thank all the coders and witnesses who have been instrumental to HF20, previous hard-forks and non-consensus codebases. At times of stress we need to maintain an appreciation of the work everyone does and continues to do, even as confusion and disappointment is rampant.
We need a fallback if hardforks don't go to plan
^^^ That's the TLDR; of it ^^^
Here's what should have happened this time around.
The happy path
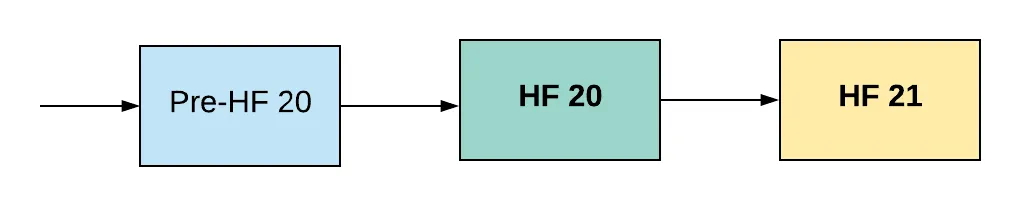
HF20 is adopted, everything goes well and we move onward, towards HF21 eventually (SMTs are still on the way...)
The core problem here is that it assumes that everything is going to work out. Developers call this the "happy path", the way that things go when all assumptions are met, code works and is bug free, and maybe most importantly - users behave in the predictable way you, well, predict.
What actually happened
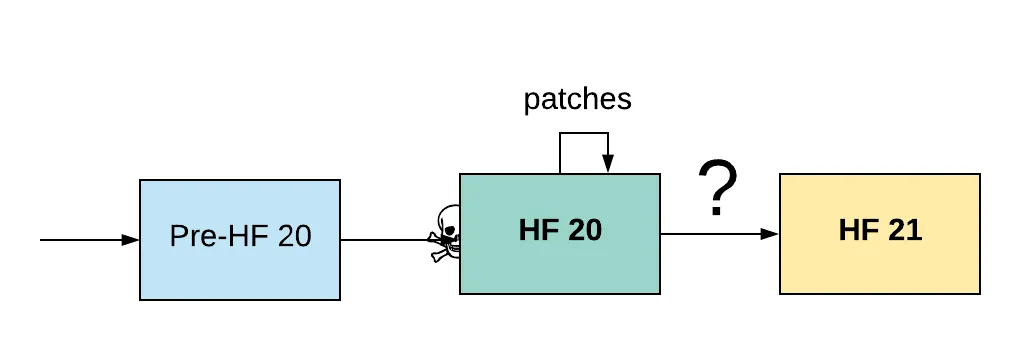
It turned out that the Resource Credits system plunged everyone (or nearly everyone) into massive negative balances, as well as some other issues. The network was unusable. Patches were made on the live network, which means that code was written to fix things and then deployed to production servers. That's jargon for servers which are actively serving the public right now.
To all involved, I know that if you spot the problem and can think of a fix, it's very tempting to continue with what you have and just patch it. Sometimes it's the most pragmatic thing to do on balance. There is a rather large cost in every way to going back: infrastructure resources, time to users, PR for not having gone forward (can be a cardinal sin in some circles), etc. I've done it myself!
However here's what should have happened, in my humble, not completely informed, opinion:
A pre-prepared fallback patch is adopted
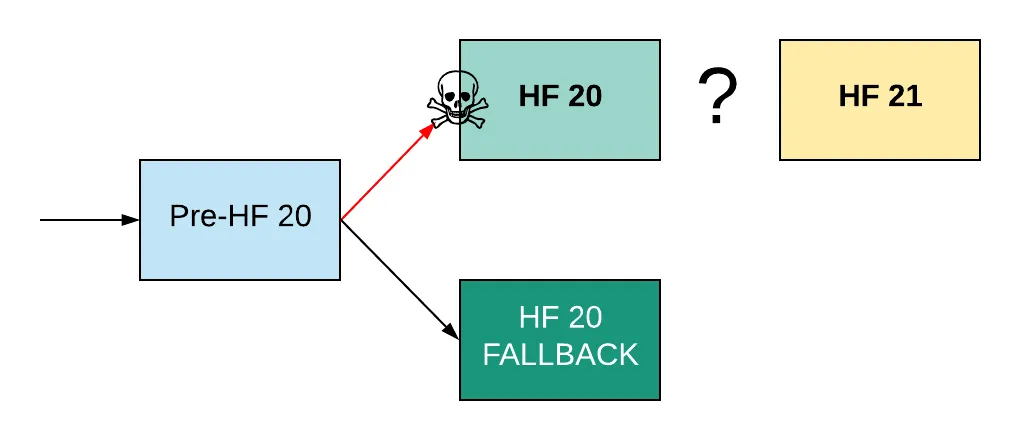
The problem with "going back" to the last code revision before HF20 is adopted (this might be best put as reverting the code) is that while the buggy HF20 code was in operation, blocks have been written to the chain. So if you go back those blocks will not make sense to the old code, causing another chain halt. Your options are to:
- Go back, not only to the pre-HF20 code but also to the last block created by pre-HF20 code, or
- Write a patch which will make as much of HF20 blocks "legal" (at least not invalid) but with the same functionality as pre-HF20 code
Option 1 is almost certainly out as most people will dislike the idea of rewriting history - as they should! Important transactions could have been made there which will not now be made, or made based on information which is now known by all parties but which was not before, etc. etc.
Option 2 is the one presented in the diagram. And in order for this not to be a crazy scramble it needs to have been prepared in advance. That said it could be done now, but just with almost the same uncertainty as patching HF20 in general.
But where do we go from there? We need to keep staging things this way:
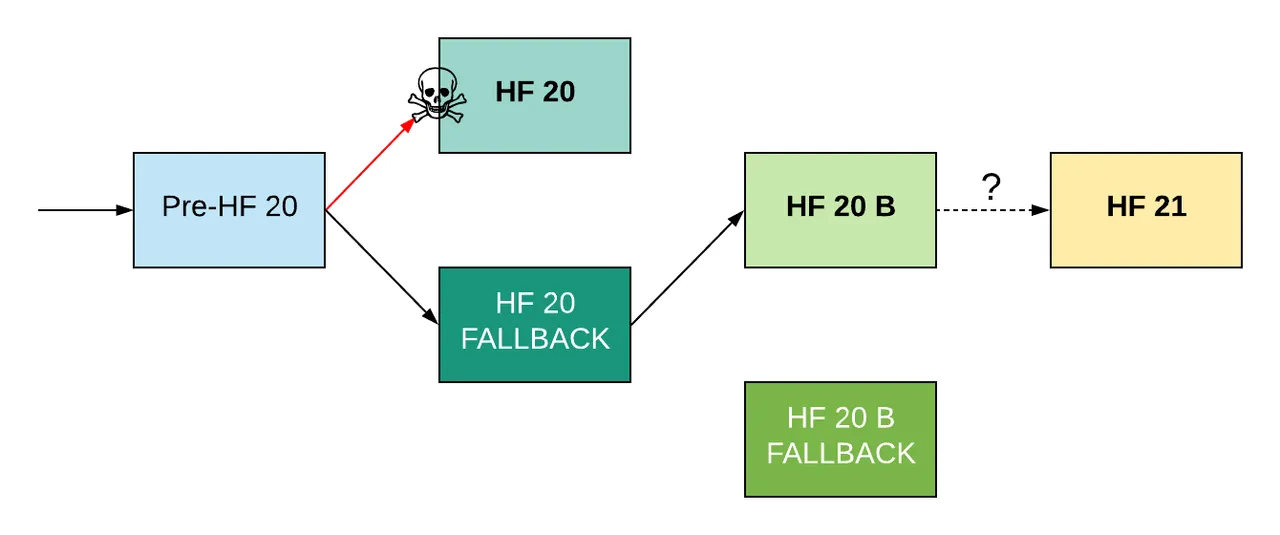
This is the contented path, with additional fallbacks. If the patches then work out, we can have HF20 adopted with minimal outages to many (or most!) users, and even rethink HF20 if necessary. Perhaps what we learned in the first round of errors brings up new information we didn't know before. We need time to react to that and be open to changing path if required to.
Then we can go forward to HF21 with out thinking as we did at the start (see first image) that there is no uncertainty, and without the huge uncertainty we now face, but with a reduced and acknowledged level of uncertainty.
Backing savvy witnesses
As others have stated here, here and here, we need to support witnesses who get this kind of thinking, who default to "go back and fix" instead of "keep patching and fix" on the live network. We need to support witnesses who perhaps even sponsor the testing of hardforks beyond the level we're doing now.
But no amount of testing can completely prepare you. We could use a fallback process such as the one I describe here to be the plan B I really wish we had right now.
Final thought. I'm not tied to this particular solution as such, it was just an idea I had and point I wanted to make noise about. Whatever averts massive outages such as this, and keeps low SP users in the game without days of "balancing" outage, we need that.