[DA series - Learn Python with Steem] 是DA(@deanliu & @antonsteemit)關於「從Python程式語言實做Steem區塊鏈的入門」的系列,歡迎趕緊入列學習!
前情提要:[DA series - Learn Python with Steem #10] Steem 小工具DIY #2 - 我的文章列表(一)

第#11堂課,嗨,繼續Python學習之旅,今天繼續「Steem 小工具」系列吧!
Steem 小工具DIY #3 - 我的文章列表(二)
上次我們學到如何製作「查詢自己發文紀錄」的小工具,今天我們更進一步,除了爬出文章列表之外,再把一些基本信息也一起抓取回來,並且練習「輸出成檔案」的步驟。就讓我們快點開始吧!
文章信息
記得上次實做中,我們透過Steem類別中.get_account_history()這個method來取得我們在STEEM鏈上從古早以前到今天的所有交易資料,再過濾出屬於「發文」的紀錄。而每一筆「發文」中,也都含有permlink以及author,當時說過這兩者相加,就是一篇貼文在區塊鏈上獨一無二的識別碼,今天我們正是要利用兩個參數來「定位」區塊鏈上的這篇貼文,並且抓取特定資料。我們今天一共會多用到steem函式庫裡面的兩個函式,也都是差不多的使用方式,分別是:
.get_content():回傳本文的基礎內容.get_reblogged_by():回傳所有轉發(reblog)此文的使用者。
就讓我們大概來看一下這些method回傳的東西長怎麼樣吧!
get_content()ㄉ
關於這些method的用法,我們都可以簡單自己用一篇自己的貼文測試一下:例如 @antonsteemit的發文くら寿司 藏壽司,在網址的地方就可以輕鬆的發現這樣的網址格式: https://steemit.com/主分類/@author/pernlink。因此我在這裡先為了測試方便,在腳本中把author和permlink這兩個變數寫死,接著試試看直接丟到s.get_content()中,看看結果為何:
from steem import Steem
s = Steem()
author = 'antonsteemit'
permlink = 'kura-sushi'
content = s.get_content(author, permlink)
for _key, _value in content.items():
print('[{}]\n {}'.format(_key, _value))
我在上述程式最末段使用這樣的語法:
for _key, _value in content.items():
道理就跟解開一個Dictionary是一樣的,因為知道回傳回來的東西將會是key=>value這樣子的配對,所以透過這樣拆解可以清楚的知道這個content裡面有哪些keys,又可以透過這些keys拿到哪些結果。
[body_length]
0
[total_pending_payout_value]
0.000 STEEM
[total_payout_value]
4.389 SBD
[root_author]
antonsteemit
[total_vote_weight]
0
[root_permlink]
kura-sushi
[curator_payout_value]
0.989 SBD
[abs_rshares]
0
...
其中基本上所有我們需要的訊息都可以從這裡拿到了,除了發現reblogged_by這個欄位似乎是錯誤的,不論傳入什麼文章都顯示沒有reblog紀錄。所以我們需要用到另外一個獨立的method來獲取一篇文章被分享的次數。
這裡大家可以開始選擇自己想要選取哪些細節記入自己的表單之中。在此選擇了title, created(創立時間), net_votes (upvote數量-downvote數量), children(回文數量),最後就是關於最終收益的total_payout_value,curator_payout_value,pending_payout_value。
get_reblogged_by()
上面說到了,用get_content()去出來的資料在reblog紀錄方面有點問題,不過Steem函式庫也提供了這個獨立的method: get_reblogged_by()來查詢一篇文章轉發狀況。我們一樣可以先寫一小段程式測試一下這個method:
from steem import Steem
s = Steem()
author = 'antonsteemit'
permlink = 'kura-sushi'
reblogs = s.get_reblogged_by(author, permlink)
print(reblogs)
執行結果:
['antonsteemit']
有點尷尬的,沒有人轉發這篇貼文,不過沒關係,很正常啦!。但至少我們現在知道這個method呼叫之後是回傳一個List of User,所以我們只要使用 len()這個測量長度的函式,就可以知道有「多少人轉發」了:
count_reblog = len(reblogs) - 1
要減一是因為要扣掉自己阿!
模組化 -- Function撰寫
好了現在我們幾乎所有需要的東西,只要透過author以及permlink, 有大部份可以透過第一個method:s.get_content()來獲得,後面只要使用content['key']這樣的語法就可以選取想要的內容;另外關於「轉發數」,也可以獨立透過s.get_reblogged_by()來完成。我們可以將這個程式的「構造」列的清晰一點,先定義一個叫做get_post_detail()的函數,輸入author跟permlink就抓取所有我們需要的Data:
def get_post_detail(author, permlink):
content = s.get_content(author, permlink)
title = content['title']
created = content['created']
count_votes = content['net_votes']
count_replies = content['children']
total_payout_value = content['total_payout_value']
pending_payout_value = content['pending_payout_value']
reblogs = s.get_reblogged_by(author, permlink)
count_reblogs = len(reblogs) -1
return {'title':title, 'created':created, 'count_votes':count_votes, 'count_replies':count_replies, 'total_payout_value':total_payout_value, 'pending_payout_value':pending_payout_value, 'count_reblogs':count_reblogs}
這裡最後設計成回傳一個dictionary,個人覺得在未來取用裡面內容時比較明瞭。我可以用自己的author和permlink試跑看看:
(get_post_detail('antonsteemit', 'kura-sushi'))
執行結果:
{'count_reblogs': 0, 'title': 'くら寿司 藏壽司 Kura Sushi - 迴轉壽司來囉 (近台北車站)', 'count_votes': 19,'total_payout_value': '4.389 SBD', 'count_replies': 6, 'created': '2018-07-29T16:15:24', 'pending_payout_value': '0.000 SBD'}
與小工具1的整合
還記得上次製作的小工具中,我們可以透過迴圈列出我們的發文紀錄以及permlink了,接著我們還透過一個名叫permlink_list的List物件存下我們所有的permlink,我們現在只要透過一個迴圈將這些permlink一個一個丟進我們剛剛客製化好的get_post_detail()函式,就可以得到每一篇的結果了。
首先先去把上週的程式翻出來,直接複製貼上過來(然後可以把上次的print()部份改掉),只要在最後面加上一個迴圈,並且通過我麼的程式,印點東西出來看看,真的沒錯就可以準備寫檔了:
for permlink in permlink_list:
detail = get_post_detail(account_name, permlink)
print('{} [$ {}] {} '.format(detail['created'], detail['total_payout_value'], detail['title']))
執行: python get_post_history_advanced.py antonsteemit
結果:
2017-11-14T05:08:06 [$ 0.094 SBD] A Rule to keep in mind for All Crypto Investors
2017-11-14T07:57:45 [$ 0.000 SBD] Want to send you some postcards from Taiwan!
2017-11-14T08:45:57 [$ 0.020 SBD] Great Jazz Music Live Streaming that just made my day! 下午茶爵士樂分享
2017-11-14T09:48:12 [$ 1.281 SBD] Some Quotes from "Let's say, How many Efforts have you Ever Made?" 中/英
2017-11-14T10:38:36 [$ 0.000 SBD] While Mining on my GPU...
2017-11-14T11:21:27 [$ 0.048 SBD] 給對未來徬徨的你:比起平庸,努力從來不是一件辛苦的事情 -- 王遠成 <老實說你做過多少努力>
2017-11-14T12:47:42 [$ 0.000 SBD] Why do people still think the Earth is flat?
2017-11-15T15:18:42 [$ 2.788 SBD] When you are still Young, Try to Do Something more Important than Networking. -- 趁年輕,去做比維護人脈更重要的事情
2017-11-16T01:39:21 [$ 0.121 SBD] UGH, workday again?
2017-11-16T17:38:06 [$ 2.512 SBD] Amazing Scenery @ Hanging Rock, NC, USA 美國旅遊篇
2017-11-17T08:23:18 [$ 17.006 SBD] Hi Steemit, This is Anton From Taiwan :) Anton的自我介紹
...
檔案輸出
大概執行一下都沒有問題,就可以按ctr+c結束程式了。最後進入我們這個小工具教學的最後一步,輸出成檔。這步其實很簡單,就是把資料類似print()一樣印出來,只是每次是寫到一個檔案裡,只要格式正確,就可以變成.xls或是.csv等等到哪裡都打的開的檔案。基本上這些檔案的規定都是利用逗號(,)作為資料的分隔符號,只要像我們print()字串時一樣的把所有內容轉成字串就行了。其中寫檔的方法千千百百種,我們可以先使用最陽春的open()開檔讀寫函式來練習,以下是基本的寫檔語法:
file_name = 'output.csv'
file = open(file_name, 'w', encoding='utf-8')
file.write('test,writing \n')
open()函式第一個參數就是檔案名稱,這沒什麼特別的。其中比較需要注意的是的第二個參數'w'其實指的是開檔權限,w是指write,代表我想要寫入這個檔案。而其他還有read(r)就代表只要讀取、append(a)代表接續寫檔等等,可以避免我們不小心寫了不該改的檔等等悲劇發生。這裡我們是要寫入的,所以權限為'w'。
而第三個參數則是編碼(encoding),是一門非常深奧的學問。簡單的說所有的字串在真正存到電腦裡時會用不同的「規則」(也就是編碼)來轉換成電腦看懂的010101,不同編碼可能支援不同語言或是符號,這就是為什麼有時候windows跟mac的檔案通用會有亂碼問題。建議大家都養成習慣使用encoding='utf-8',俗稱萬國碼,是最為通用的編碼。
還有,字串最後用到的\n代表的是換行的意思,如果沒有加上換行的話,可能下一個迴圈寫入的值就會直接接在這個迴圈的最後面。我們最後是希望印出類似excel表單一樣的整齊格式,所以一定要乖乖換行啦。
所以在最後permlink_list的迴圈前後更改如下:
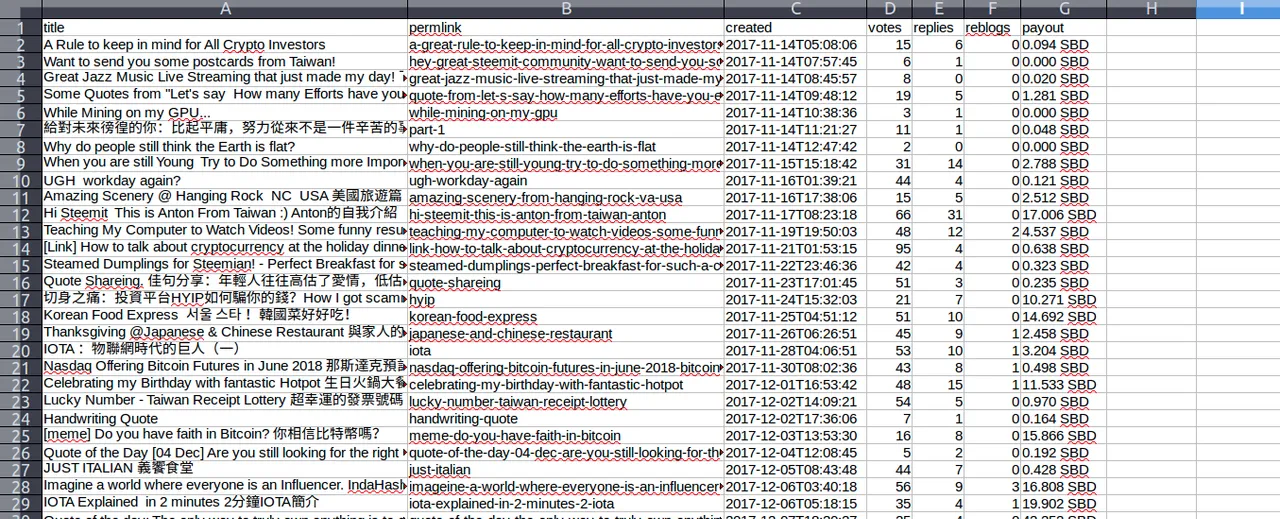
## Write Output
file_name = '{}_post_history.csv'.format(account_name)
file = open(file_name, 'w', encoding='utf-8')
file.write('title,permlink,created,votes,replies,reblogs,payout\n')
for permlink in permlink_list:
detail = get_post_detail(account_name, permlink)
file.write('{},{},{},{},{},{},{}\n'.format(detail['title'].replace(',',' '), permlink, detail['created'], detail['count_votes'], detail['count_replies'], detail['count_reblogs'], detail['total_payout_value'] ))
還要注意到一個很小的小細節,就是記得我們剛剛說過csv或是excel檔是透過,來分「格子」,所以如果我們的title內有包含,的話(或是你要儲存內文的話也很有可能),就會被當作一個分隔子。所以我利用了字串的一個的method叫做.replace('a','b'):把所有的a取代為b,我設定將title裡面的','都取代成功字串'',這麼一來印出來的格式就會整齊劃一啦!
最後提供一下這個程式的原貌:get_post_history_advanced.py
運行完會得到一份antonsteemit_post_history.csv的文件,在使用應用程式開啟時可能要選擇一下編碼為utf-8(視不同應用程式而定。)開啟完成就看到一份美如畫的報表啦!
回家作業:
做出屬於自己的「發文記錄器」,然後分享一下自己選擇紀錄的內容、還有最終產品吧!

image - pixabay