早前,我介绍了循环神经网络(RNN)的基本概念,这篇文章我们就用Keras搭建一个RNN网络。该RNN能够通过对历史数据的学习,预测未来数据。
同样的,为了方便与读者交流,所有的代码都放在了这里:
Repository:
https://github.com/zht007/tensorflow-practice
1. GRU和LSTM简介
GRU(Gated Recurrent Unit)和LSTM(Long Short Term Memory)都是改进的RRN结构,为了解决深度RNN中容易出现的Vanishing Gradient(梯度消失)的问题。
关于梯度消失和梯度爆炸有机会可以单独介绍,简单来说就是浅层神经元在传递过程中由于多次的累乘作用,其权重趋近于无穷大或者趋近于零的现象,从而无法再有效地学习。
梯度消失和梯度爆炸在深度神经网络中非常容易出现,对于RNN来说,梯度消失现象尤为明显。RNN通常处理时间序列的问题,位于时间轴前面的信息很容易在深度网络中由于梯度消失现象,很容易就被"遗忘"掉。
GRU和LSTM就是加入了记忆的功能,从而有效地解决了这个问题。LSTM有Forget Gate和 Update Gate,而GRU简化成了一个Gate。目前GRU由于占用资源更少在大多数情况下已经够用了。
2. 数据导入和查看
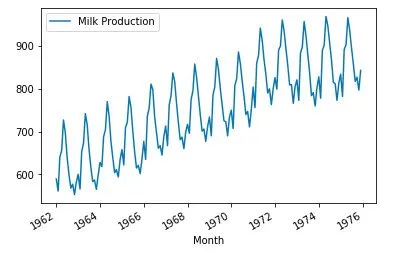
本文的数据来自这里with open lisence,这个数据集记录了从1962年到1975年某地每个月牛奶的产量,是一个典型的有规律的时间序列数据,如下图。
注意,源代码中文将数据放在了Google Drive中方便在Colab中直接处理,也可以将csv文件放在本地,在本地运行。
milk.plot()
3. 数据预处理
首先,我们将数据分为训练组和验证组,这里一共有14年的数据,我将前13年的数据用于训练,最后一年的数据用于验证。
train_set= milk.head((1976-1962-1)*12)
test_set = milk.tail(12)
然后,我们用sklearn的MinMax工具对数据进行归一化处理。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
train_scaled = scaler.fit_transform(train_set)
test_scaled = scaler.transform(test_set)
接着,我们需要对训练集的数据再次处理以符合RNN和GUR的输入输出的Shape。
设计一个连续的数据窗口,窗口中包含13个月的数据。
由于是多对一的结构,前12个月数据X为输入的Feature,后1个月数据为label与神经网络的输出做对比。
数据窗口按月平移,这样一共可以产生12*12个组数据。
def build_train_data(data, past_monthes = 12, future_monthes = 1):
X_train, Y_train = [],[]
for i in range(data.shape[0] + 1 - past_monthes - future_monthes):
X_train.append(np.array(data[i:i + past_monthes]))
Y_train.append(np.array(data[i + past_monthes:i + past_monthes + future_monthes]))
return np.array(X_train).reshape([-1,12]), np.array(Y_train).reshape([-1,1])
于是我们通过这个帮助函数得到输入和输出
x, y = build_train_data(train_scaled)
4. GRU的输入与输出
from tensorflow.keras import layers, Sequential,models
RNN_CELLSIZE = 10
SEQLEN = 12
BATCHSIZE = 10
如下图所示,
输入:X shape [BATCHSIZE, SEQLEN, 1],SEQLEN是输入步长,这里为12。
输出:Y shape [BATCHSIZE, SEQLEN, 1],但是我们这里是多对一的结构,仅取最后一位即可。
状态:H shape [BATCHSIZE, RNN_CELLSIZE*N_LAYERS], RNN_CELLSIZE是每一层GRU个数,N_LAYERS是神经网络的深度(层数)
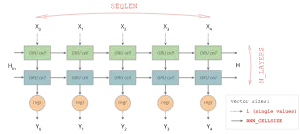
image source from github with lisence Apache-2.0
5. GRU神经网络
5.1 单层GRU结构
在Keras中,Batchsize是隐性表示出来的,所以不必给出。Reshape的目的是保证X shape 为[BATCHSIZE, SEQLEN, 1]。GRU默认只输出Y的最后一位,最后通过单神经元全连接层输出。
model_layers = [
layers.Reshape((SEQLEN,1),input_shape=(SEQLEN,)),
layers.GRU(RNN_CELLSIZE),
layers.Dense(1)
]
model = Sequential(model_layers)
model.summary()
------OUTPUT-------------
Layer (type) Output Shape Param #
=================================================================
reshape (Reshape) (None, 12, 1) 0
_________________________________________________________________
gru (GRU) (None, 10) 630
_________________________________________________________________
dense (Dense) (None, 1) 11
=================================================================
部分代码参考 github with lisence Apache-2.0
5.2 两(多)层GRU结构
在Keras中增加GRU中间层,需要设置return_sequences=True,中间所有的输出都可以传到下一层,而不是默认的只输出最后一位。
model_layers = [
layers.Reshape((SEQLEN,1),input_shape=(SEQLEN,)),
layers.GRU(RNN_CELLSIZE, return_sequences=True),
layers.GRU(RNN_CELLSIZE),
layers.Dense(1)
]
model = Sequential(model_layers)
model.summary()
------OUTPUT-------------
Layer (type) Output Shape Param #
=================================================================
reshape (Reshape) (None, 12, 1) 0
_________________________________________________________________
gru (GRU) (None, 12, 10) 360
_________________________________________________________________
gru_1 (GRU) (None, 10) 630
_________________________________________________________________
dense (Dense) (None, 1) 11
=================================================================
部分代码参考 github with lisence Apache-2.0
5.3 模型的训练
这里模型compile 和 模型 fit 与之前CNN没有太大区别
model.compile(
loss = 'mean_squared_error',
optimizer = 'adam'
)
h = model.fit(x,y, batch_size=BATCHSIZE,
epochs = 1000)
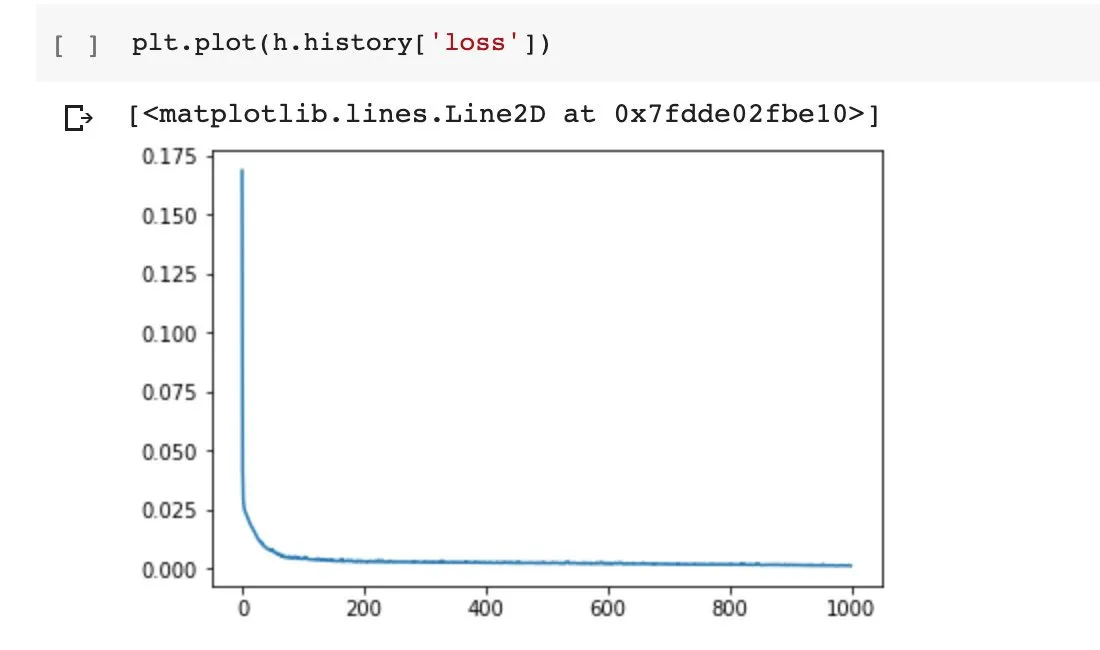
可以看到经过1000个epoch的训练,在样本不大的情况下损失函数稳定在0.02左右。
6. 模型的预测
6.1 预测最后一年
对于多对一的模型,由于每输入12个月只能预测1个月的结果,我们需要取训练集中最后一年12个月的产量,来预测下一年中第一个月的产量。然后再将这个月预测的产量放进输入以预测第二个月的产量,如此循环12次便能预测全年的产量了。
我们需要一个帮助函数:
def get_prediction(data_list):
predict = []
train_seed = data_list
for i in range(12):
x_train = np.array(train_seed[-12:]).reshape(1,12)
one_predict = model.predict(x_train)[0][0]
predict.append(one_predict)
train_seed.append(one_predict)
return predict, train_seed
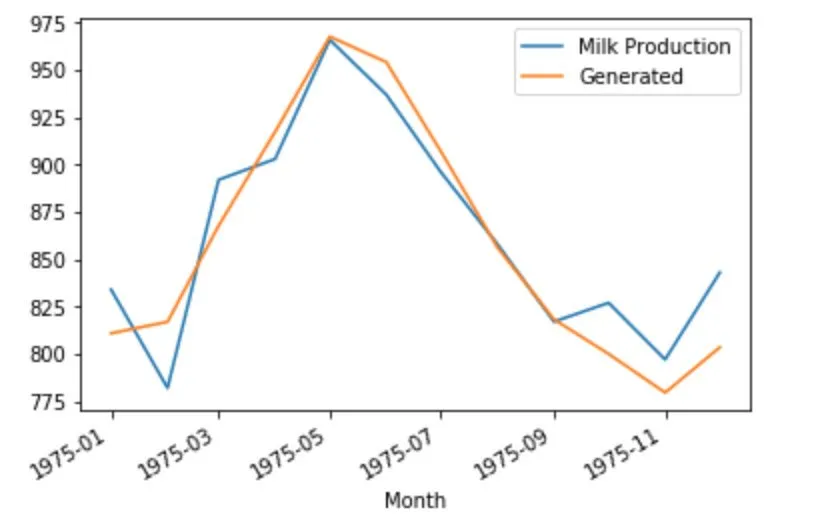
将训练集中最后12个月的数据取出,来预测下一年的产量。
train_seed = list(train_scaled[-12:].flatten())
predict, train_seed = get_prediction(train_seed)
经过一些简单处理,我们可以看到预测结果和实际结果(测试集数据)之间的对比。
6.2 进一步预测
当然我们也可以仅用第一年的数据来预测所有之后的数据,结果如下,具体过程可参考源码。
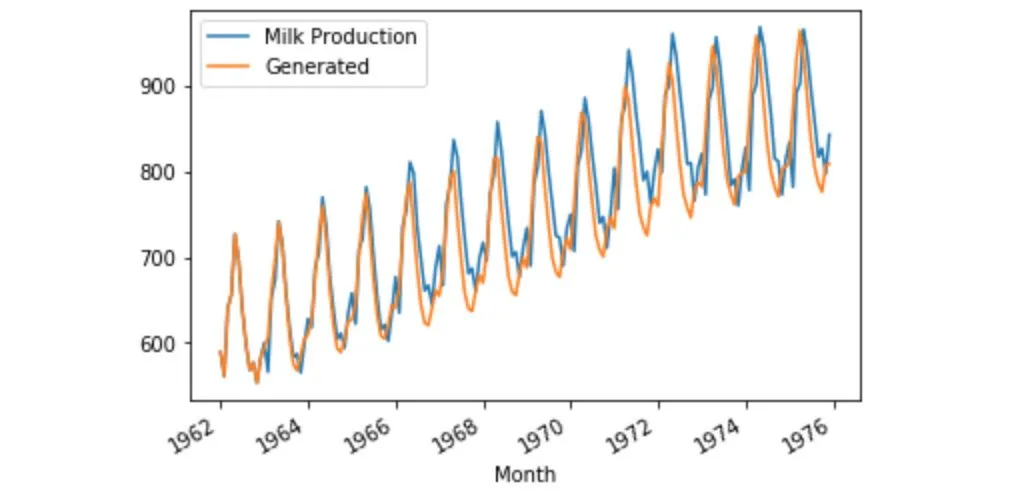
总结
本文通过Keras实现了单层或多层GRU结构,采用多对一的结构,通过前12个月牛奶的产量成功预测下一个月的产量。我们是否可以采用多对多的结构,用前12个月的产量预测后12个月的产量呢?答案当然是肯定的,这个问题将在下一篇文中解答。
参考资料
[1]https://codelabs.developers.google.com/codelabs/cloud-tensorflow-mnist/#0
[2]https://github.com/GoogleCloudPlatform/tensorflow-without-a-phd.git
[3]https://www.tensorflow.org/api_docs/
相关文章
Tensorflow入门——单层神经网络识别MNIST手写数字
Tensorflow入门——多层神经网络MNIST手写数字识别
Tensorflow入门——分类问题cross_entropy的选择
同步到我的简书